
千万级并发下,系统为何突然崩了?
别急着骂服务器不够猛。真正压垮系统的,往往不是流量本身,而是架构没经得起真实世界的“暴力测试”。
你看到的卡顿、挂机,其实是请求在层层堵车——网关扛不住、数据库锁死、缓存穿透、消息积压……一个环节掉链子,整条链路直接雪崩。
这不是靠多买几台机器就能解决的,说白了,得提前把坑踩完,不然等上线才现学,那可就真成“灾难现场”了。
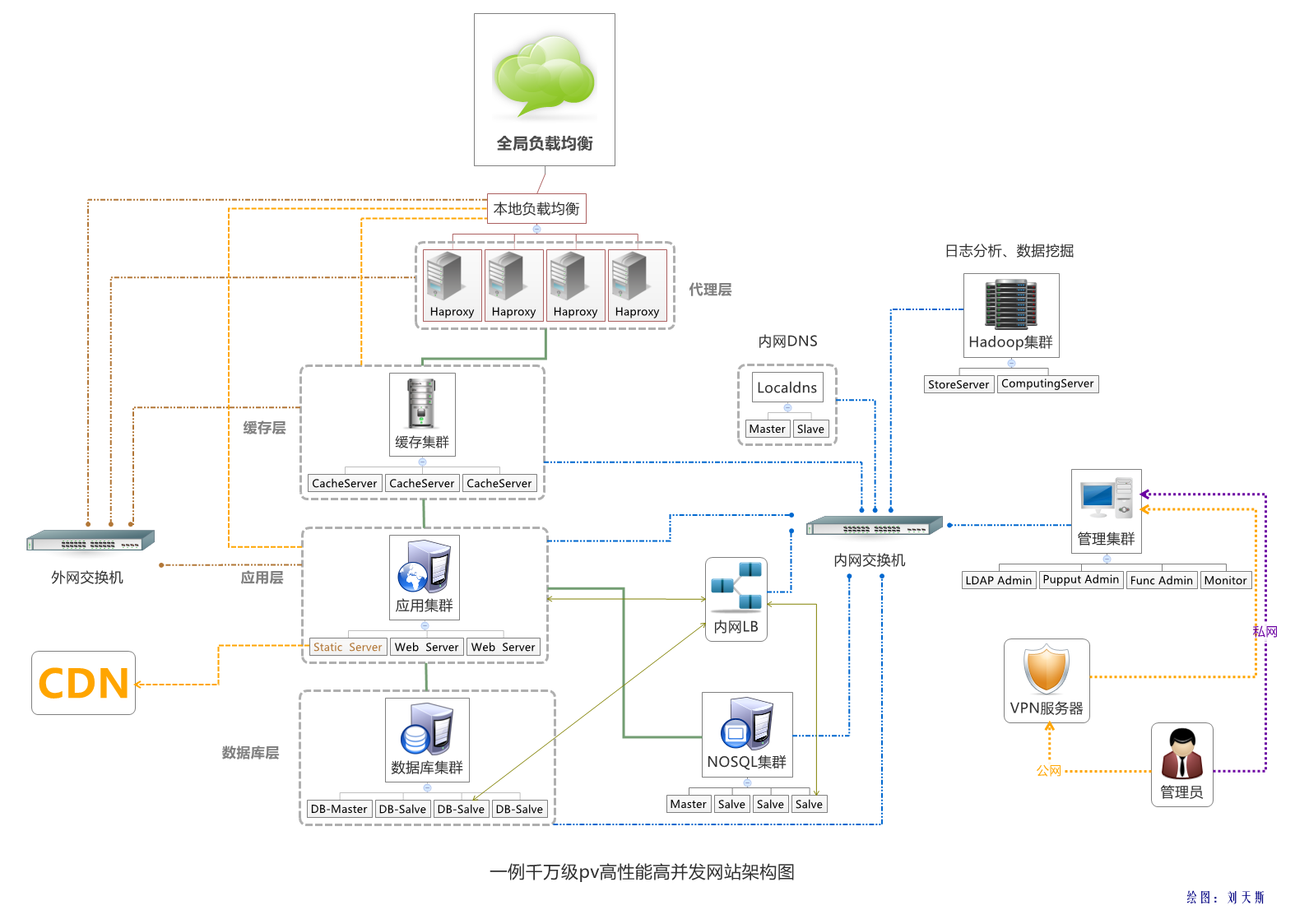
接入层:第一道门不能成摆设
反向代理和负载均衡是标配,用 Nginx LVS 搭集群,听起来挺靠谱,但千万别只配一台主节点。
真要命的是,一旦主节点心跳断了,整个入口瞬间瘫痪——这事儿我见过不止一次,血泪教训。
必须上主从热备(Keepalived),哪怕多花点配置时间,也比事后救火强。
服务网关也别当摆设。所有请求都得走它,做鉴权、限流、日志记录,这些事它得顶住。
但说实话,别指望它能挡住所有攻击。恶意请求冲破限流阈值后,照样能把后端拖死。
所以熔断机制得真生效——失败率超过50%,或者响应超1秒,立马切断,别让下游继续被拖着跑。
同时配合降级策略,比如登录失败直接返回“请稍后再试”,而不是让前端一直轮询,白白浪费资源。
✅ 实操提醒:云上部署时,别只开一个Nginx实例。至少3个节点打成集群,再加健康检查脚本。要是某节点挂了,不自动剔除,那流量全砸它身上,等于自找麻烦。
数据库:别再拿单点硬撑了
一张订单表存到一亿行,哪怕有索引,查起来也跟蜗牛爬一样。尤其高并发写入场景下,锁竞争直接导致事务排队,后面的人只能干等。
分库分表听着很高级,但真不是万能药。
按 user_id % 128 分片看似简单,可万一用户量翻倍,重新分片就是一场数据迁移噩梦。
建议先用 ShardingSphere 这类中间件,支持动态分片,但代价是运维复杂度飙升,小团队容易吃不消。
读写分离也得看情况。主库写,从库读,听起来合理,可从库延迟可能高达几秒。
如果你的业务对实时性要求高,比如余额查询,这种方案根本不行。
我见过一个项目上线后用户投诉“刚转完账,余额没变”——查下来就是主从同步延迟,而且没启用强一致性读。
✅ 真实教训:别以为读写分离就万事大吉。该加锁的地方还得加,该走直连的地方别绕路。
❌ 劝退指南:如果你的数据量小于500万条,平均响应时间控制在500毫秒内,真没必要上分库分表。省下的维护成本,比折腾架构还划算。
✅ 平替方案:用 MySQL 8.0 的窗口函数优化查询,搭配本地缓存 二级索引,日常需求基本都能搞定。
性能优化:避开90%人踩过的坑
缓存不是越多越好。
本地缓存(比如 Caffeine)适合热点小数据,但容量有限,容易被冲刷。
Redis 集群虽能跨节点共享,但网络延迟不能忽视。如果应用和缓存不在同一可用区,一次请求来回多花200毫秒以上,这账怎么算都不划算。
别把所有缓存都扔进 Redis,内存溢出、连接池耗尽的风险立马拉满。
本地缓存更适合高频访问的配置项或用户会话,这才是正道。
异步解耦确实能救命。发邮件、生成报表、推送通知这些慢活,扔进 Kafka 或 RabbitMQ,主流程压力立马轻了。
但别忘了,消息队列也会成为瓶颈。消费者处理不过来,消息堆积,最后还是卡死。
✅ 避坑提示:设置最大重试次数(建议≤3次),并开启死信队列。否则一条错误消息反复投递,可能触发数据库死锁,那可就真成“连锁反应”了。
Kubernetes 扩缩容也不是自动救世主。
它依赖预设指标(CPU/内存/请求量),可实际流量波动剧烈时,伸缩滞后严重。
比如突发大促,新实例启动要两分钟,前60秒请求全堆在那儿,用户体验直接崩了。
更现实的做法是:提前预判流量高峰,手动预热实例,别等火烧眉毛才想起来。
✅ 平替方案:用云厂商提供的弹性伸缩组(如 AWS Auto Scaling Group),结合监控告警联动,比纯靠 Kubernetes 更稳定,也更省心。
元宇宙体验不卡顿?关键在“预加载”和“轻量化”
CDN 加速是基础。3D模型、贴图、视频放 CDN 节点,让用户就近下载,没错。
但注意:文件太大时,边缘节点缓存命中率低,反而加重回源压力。
别以为用了 CDN 就万事大吉,还得看内容大小和访问模式。
预加载机制看着聪明,实则吃资源。
用户刚进房间,系统就开始加载门后内容,听上去很流畅。
可问题是,用户可能根本不会走进去,白白浪费带宽和内存。
更稳妥的做法是:根据用户移动方向预测路径,只预加载前方1~2个场景资源,既省资源又提升体验。
模型压缩真能省40%?看情况。
glTF / USDZ 格式确实更小,但转换过程需要额外处理。
LOD(细节层次)技术有效,但得配合渲染引擎逻辑。如果不用硬件加速,低精度模型照样卡顿。
最关键的是:别把原始模型全存进缓存。常用地放 Redis,中频的放本地磁盘,冷数据直接丢对象存储(如 OSS)就行。
✅ 真实案例:某平台测试发现,5万人同时在线时,3D资源加载延迟飙升。引入“按需预加载 分级缓存”后,平均响应时间从1.8秒降到0.3秒。
但前提是:用户行为可预测。若用户随机跳转,这套机制立刻失效。❌ 劝退指南:如果你的用户行为极难预测(如直播互动、自由探索),或者预算低于50万,别投入大量资源做预加载和模型优化。直接用标准3D引擎 默认加载策略,反而更稳。
✅ 平替方案:用 Three.js GLTFLoader 异步加载,无需自研框架,也能实现基本流畅体验。
系统稳定靠的是“主动找死”,不是被动等待
全链路监控必须覆盖真实路径。
用 Prometheus Grafana 看 CPU、QPS、错误率,没错。但关键是:你监控的指标能不能反映真实用户体验?
接口响应快,但页面渲染慢,用户照样觉得“卡”。
必须加入前端埋点(如 Web Vitals),才能看出真实卡顿点。别光看后台数字,那只是“假象”。
日志集中管理 ≠ 问题定位快。
ELK 能收日志,但日志爆炸时,搜索效率暴跌。每秒十万条日志,关键词检索可能要等30秒以上。
建议:只采集关键链路日志(如登录、支付、创建订单),其余用采样方式保留1%。
别让日志系统自己先崩了。
故障演练别搞形式主义。
定期模拟“数据库宕机”“网络中断”是好的,但必须做到真实断网,而不是代码里抛个异常。
否则测试结果全是假象,出了问题才发现“原来我们根本没练过”。
更狠的做法是:每月安排一次“黑盒演练”——团队不知道哪天会断,逼大家快速反应。
灰度发布要控制节奏。
新版本先推给1%用户,没问题再扩大。但别以为1%就安全。
要是这1%用户是高频操作、特定地域的,可能掩盖真实问题。
建议:按用户标签分批发布(如地区、设备类型、会员等级),更接近真实分布。
✅ 关键指标:系统可用性 ≥ 99.95% 是目标,但别盲目追求。
如果你只是中小企业,支撑10万用户以内,99.7%的可用性已经够用。过度追求指标,只会带来不必要的成本。
常见问题(FAQ)
Q1:我只有几百用户,现在就用分库分表是不是太早了?
不需要。 只有当单表数据量超过1000万,或平均响应时间持续>1秒时,才考虑分库分表。
初期用单库 索引 缓存足够,维护成本还低。
如果你属于中小团队,预算低于20万,强烈不建议使用分库分表方案,直接放弃。
Q2:Redis集群会不会比单机还贵?
不一定。 云厂商提供按需付费的 Redis 服务(如阿里云、腾讯云),成本可控。
但注意:连接数过多会导致连接池耗尽。
建议:限制每个应用实例最多连接100个连接,避免无节制建连。
Q3:元宇宙体验卡顿,是不是得买更强的服务器?
不是。 更强的服务器只是治标。真正解决卡顿的是:
缓存命中率提升
模型轻量化
边缘分发 预加载
降低用户感知延迟
别指望靠硬件堆出流畅体验,否则你会陷入“越加机器越卡”的恶性循环。
Q4:我们是小团队,能搞出千万级架构吗?
能,但代价是牺牲灵活性。
用现成云服务(如 AWS、阿里云、腾讯云)搭建标准架构,配合自动化运维工具,小团队也能支撑百万级用户。
但前提是你得接受:不能随意改底层逻辑,只能照着模板走。
Q5:要不要自己开发一套分布式框架?
不要。 用成熟的开源组件(如 Spring Cloud、Kafka、Redis Cluster) 云原生服务,比自研快10倍,且更稳定。
自研框架最大的风险是:你永远不知道下一个崩溃点在哪。
业内共识:除非你是头部平台,否则别碰自研分布式中间件。